Absolute and Relative Cell References in Excel
In this tutorial I am going to cover the difference between Absolute and Relative Cell References in Excel and show you how to use them and why they are so important.
Relative Cell References
Relative Cell references in a formula change as they are copied or filled down a spreadsheet. What this means is that the cell reference will update relative to the original cell reference as it is copied. To better understand this look at the following example:
(dont forget to download the file for this tutorial so you can follow along)
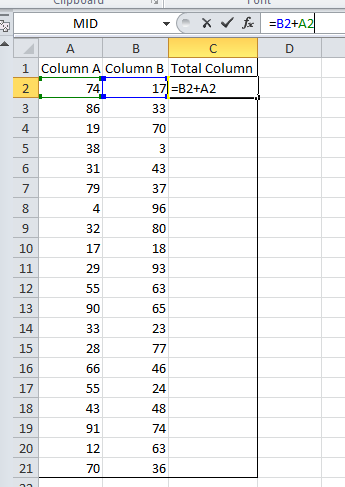
Here I have a table with 2 columns and 20 rows. I want to add column A and column B together in a Total column. I start by entering the addition formula into cell C2 which references cells A2 and B2. If you think about these cell references as relative to cell C2, I am referencing the 2 cells to the left of the current cell (C2). Now I copy my formula down the Total column:
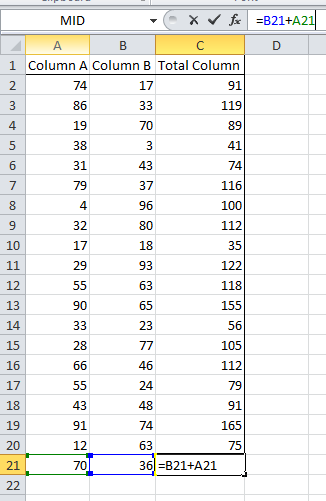
My cell references have updated relative to where I have copied my initial formula. I have cell C21 selected yet the formula now references cells A21 and B21. These 2 cells are the 2 cells to left, relative to the formula cell (C21).
Absolute Cell References
An Absolute cell reference does the opposite of a Relative cell reference. It does not update/change as a formula is copied or filled. It remains the same. This is very useful when you want to use a single value for calculations copied over a range of cells. Looking back to the previous example, I will now add a Tax column:
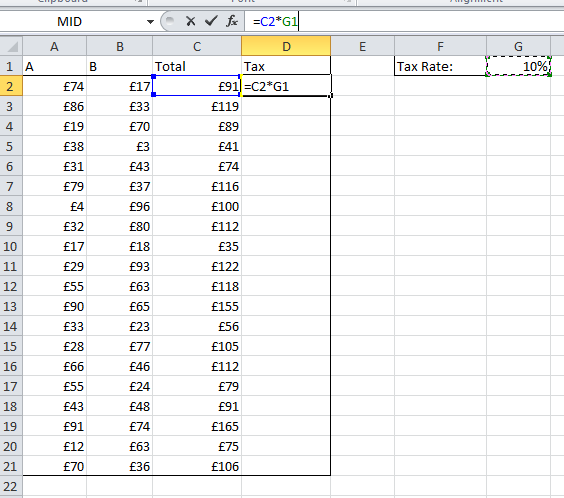
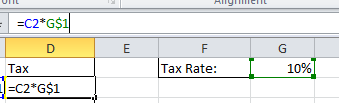
I start by entering my formula and selecting the cell G1 to incorporate my tax rate. Once I have selected the cell reference I wish to change to an Absolute cell I hit F4 on the keyboard to cycle through the Absolute cell reference options. (You can type the $ symbols that appear by hand but F4 is faster)
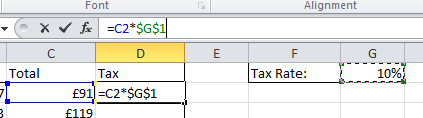
$G$1 is the absolute cell reference.
This cell reference wont change at all whether you copy the formula down the rows or across the columns. So if I copy the formula in D2 down to D21:
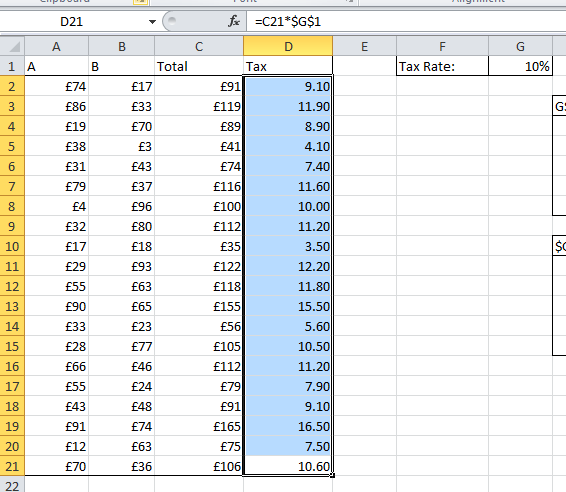
Notice that the Absolute cell reference $G$1 doesnt change.
The other Absolute cell references you can do are:
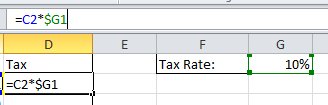
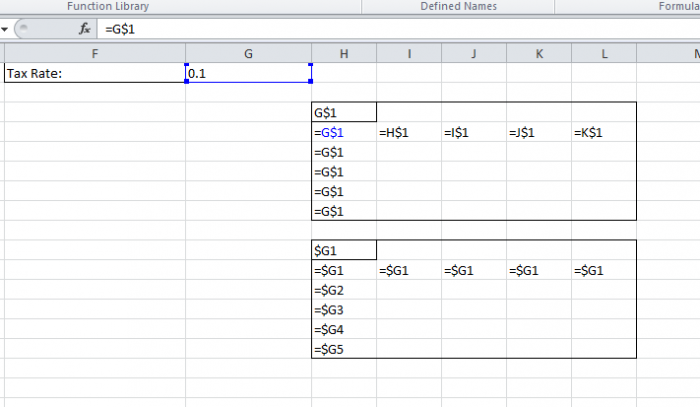
G$1 This cell reference wont change if you copy the formula down the rows but will change its column reference as it is copied across the columns.
$G1 This cell reference wont change if you copy the formula across the columns but will change its row reference as it is copied down the rows.
The dollar sign $ is what makes the elements of a cell reference Absolute.
Look at how these Absolute cell references change as they are copied down the rows or columns:
Absolute Cell References Across Different Worksheets in Excel
Absolute and Relative cell references also work across different sheets. Just start entering your formula:

Then select the next worksheet and select the cell or range you want:
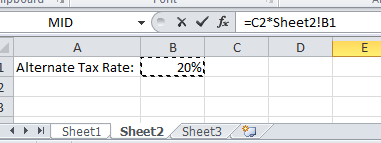
Hit F4 to get the Absolute cell reference and then Enter and you will be returned to the original worksheet:
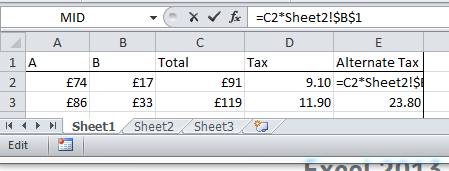
You can then copy the formula like normal:
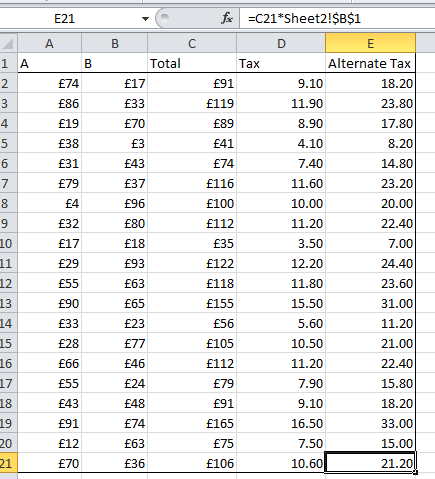
Dont be put off by the extra-long cell reference here. It works the exact same way. It is just longer due to the Sheet2! part which is what references the cell on the Sheet2 worksheet.
Dont forget about Absolute and Relative cell references! They are very important for making powerful and useful formulas and functions in Excel!
Question? Ask it in our Excel Forum
Excel VBA Course - From Beginner to Expert
200+ Video Lessons 50+ Hours of Instruction 200+ Excel Guides
Become a master of VBA and Macros in Excel and learn how to automate all of your tasks in Excel with this online course. (No VBA experience required.)
Tutorial: How to calculate the percentage amount that a value has changed in Excel. This includes q...
Tutorial: How to use a single formula to apply conditional formatting to multiple cells at once in ...
Tutorial: How to make a drop down menu list using data validation and dynamic arrays in Excel 365. ...
Tutorial: In Microsoft Excel you reference columns as letters by default - A1, B3, C5, etc. But you ...
Macro: This free Excel UDF outputs all text from a comment in Excel. This benefit of this UDF is ...
Tutorial: How to insert, remove, and manage page breaks in Excel. This can be rather annoying and...
Subscribe for Weekly Tutorials
BONUS: subscribe now to download our Top Tutorials Ebook!
Excel VBA Course - From Beginner to Expert
200+ Video Lessons
50+ Hours of Video
200+ Excel Guides
Become a master of VBA and Macros in Excel and learn how to automate all of your tasks in Excel with this online course. (No VBA experience required.)